Meilensteine
M1.1
Anforderungsanalyse, Datentestbed, kollaborative Entwicklungsumgebung und erste Iteration der Ontologie-Entwicklungsmethodologie
Für den Aufbau der Entwicklungsumgebung und um die Projektpartner in die Lage zu versetzen, an der MatVoc Ontologie zu arbeiten, wurden folgende Werkzeuge und Methoden ausgewählt:
- Das Konsortium verwendet GitHub als zentralen Punkt für die Kommunikation zu Ontologie-Dokumenten und -modellen. Über GitHub werden die Änderungen dokumentiert und die Probleme/Anfragen, sowie offizielle Veröffentlichungen der Ontologie verwaltet. Die MatVoc Ontologie ist unter folgendem Link zu finden: https://github.com/stream-project/ontology
- Das Team nutzt eine Instanz des webbasierten Ontologie-Visualisierungs- und Validierungssystems VoCol, um die Zusammenarbeit zwischen den Partnern zu erleichtern und die Zwischenrevisionen der Ontologie zu veröffentlichen. Die Anwendung ist unter http://www.stream-ontology.com verfügbar. Abbildung 1 zeigt die MatVoc-Ontologie 0.0.1 in der visuellen Form auf der VoCol-Instanz des Projekts.
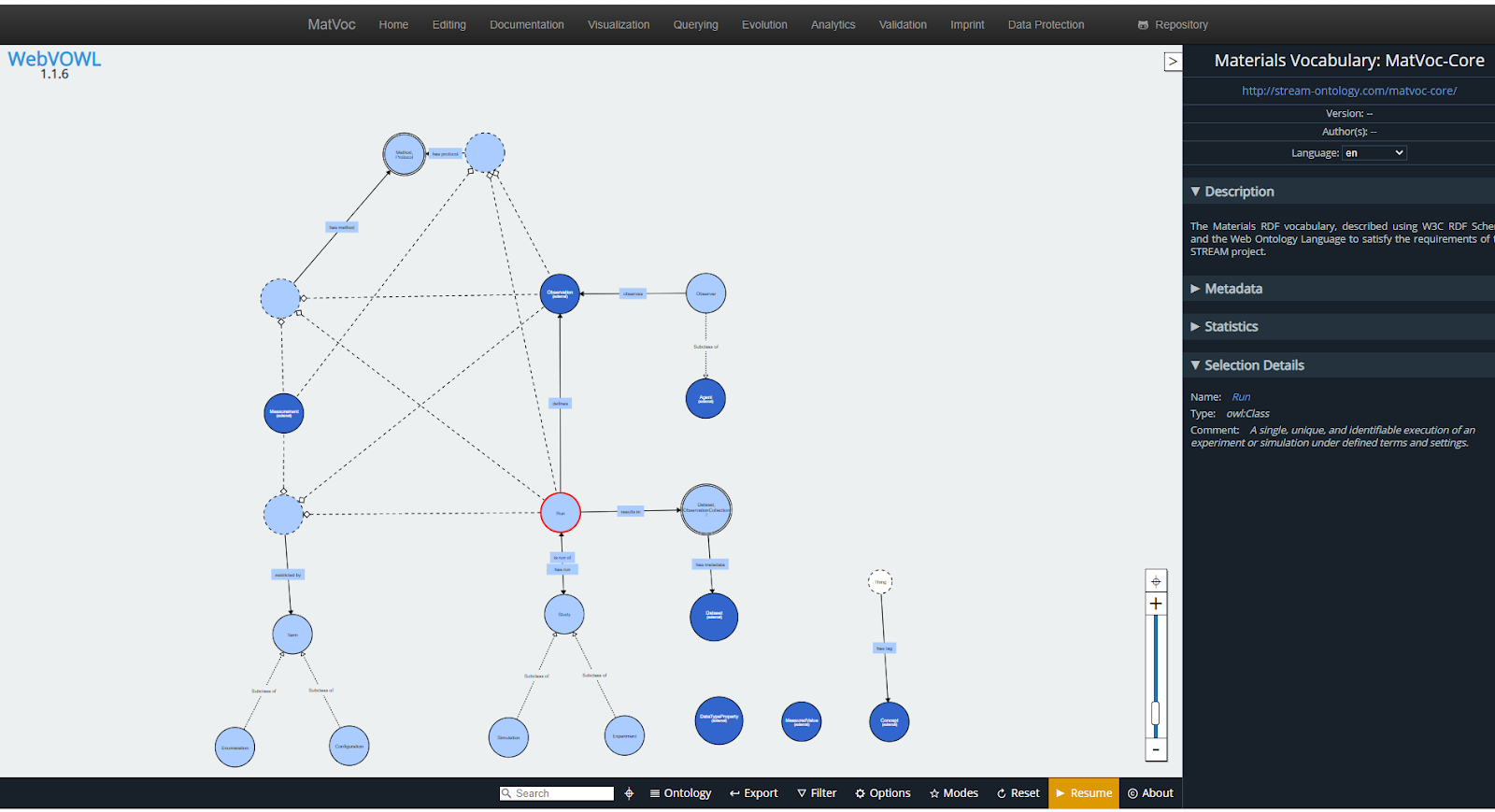
- VoCol wird außerdem dazu verwendet, den Input von Stakeholdern (über Interviews oder Workshops) zu erfassen. Für anspruchsvollere Konzeptualisierungen werden zudem die Ontologie-Entwicklungswerkzeuge Protege und WebProtege verwendet.
- Für die Definition und Serialisierung der Ontologie wurde RDF im Turtle-Format verwendet. Das ist ein einfaches und textbasiertes Format, das textbasiertes Bearbeiten, Vergleichen, Zusammenführen und die Verwendung vieler verfügbarer Texteditoren ermöglicht. Zusätzlich zu den oben genannten Tools verwendet das Team den Microsoft Visual Sudio Code-Editor zur Bearbeitung der RDF-Triple. Das Tool ermöglicht auch die kollaborative Entwicklung und Überprüfung in Echtzeit.
- Alle aufgelisteten Werkzeuge sind kostenlos und frei verfügbar.
Architektur der Ontologie
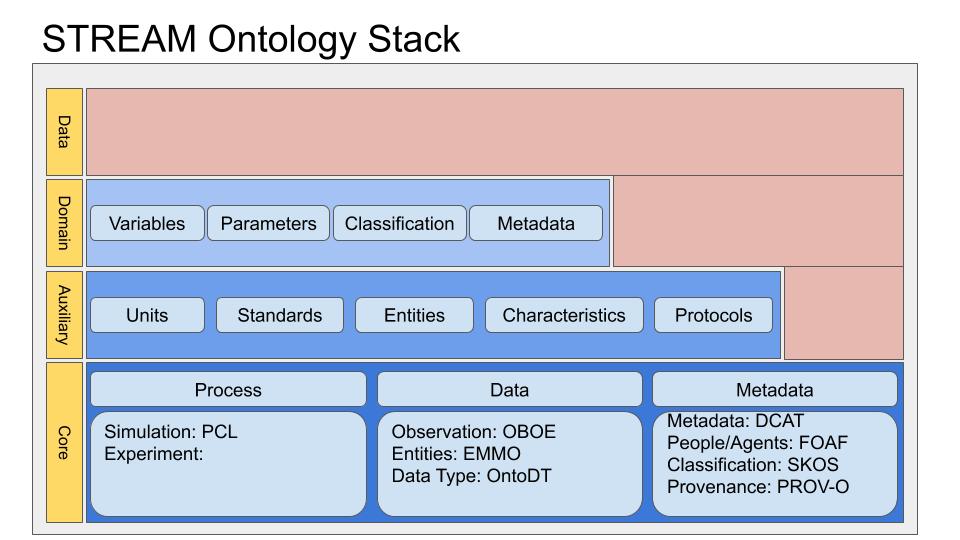
Wie in Abbildung 2 dargestellt, wurde auf Grundlage der NIST-Richtlinie zur Ontologieentwicklung eine mehrschichtige Architektur entwickelt. Diese besteht aus drei Ebenen:
- Einer kompakten Kernontologie auf oberster Ebene. Diese Kernontologie ist auf die Modellierung von Prozessen, Messungen der Modellierung von Metadaten ausgerichtet.
- Eine Reihe von Hilfsontologien auf mittlerer Ebene, um die Kernkonzepte zu erweitern und/oder zu korrigieren, z.B. Maßeinheiten, beobachtbare Entitäten und ihre Merkmale oder Standards.
- Eine Reihe von Ontologien auf unterster Ebene, die spezialisierte Domänen repräsentieren, wie z.B. NOMAD MetaInfo.
M2.1
Reifegradmodell mit initialem Portfolio an Qualitätsmetriken
MSLE-Ontologie
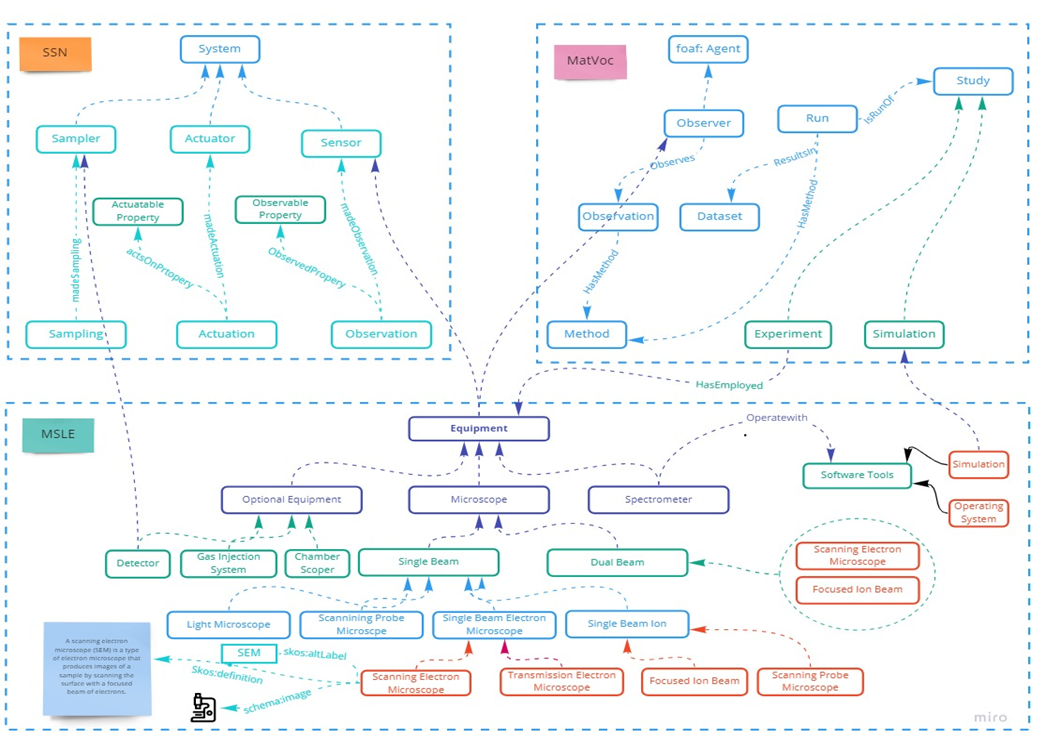
Im Rahmen des STREAM-Projekts wird die Ontologie der materialwissenschaftlichen Laborausrüstung (MSLE) entwickelt. Die MSLE-Ontologie ist eine Ontologie, die Laborgeräte in der Materialwissenschaft und im chemischen Experiment beschreibt.
Abbildung 3 zeigt die Kern-Ontologie von MSLE, die die erste Version von MSLE ist, die vom Karlsruher Institut für Technologie entwickelt wurde.
Die Phasen des Reifegradmodells – die MSLE-Ontologie als Testfall
Das Reifegradmodell bietet folgende Eigenschaften:
- Ein Maß für Auditing und Benchmarking.
- Ein Maß für die Bewertung des Fortschritts gegenüber den Zielen.
- Ein Verständnis für Stärken, Schwächen und Chancen.
Abbildung 4 veranschaulicht die vier groben Schritte beim Entwurf eines Reifegradmodells für die MSLE-Ontologie.
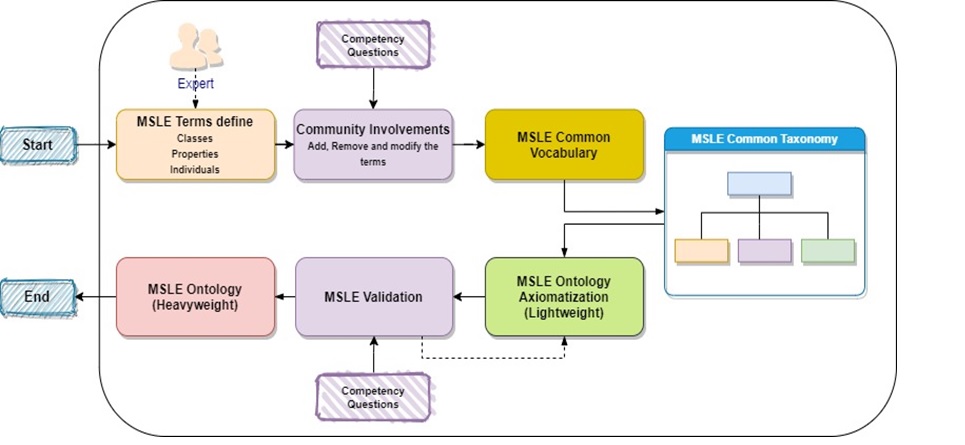
Reifegradbewertung auf Basis des definierten Reifegradmodells Eine Reifegradbewertung ist eine Untersuchung eines oder mehrerer Prozesse durch ein geschultes Team von Fachleuten unter Verwendung eines Beurteilungsmodells. Eine Reifegradbewertung kann es den Beteiligten ermöglichen, Stärken und Verbesserungspunkte klar zu identifizieren und Maßnahmen zu priorisieren, um höhere Reifegrade zu erreichen. Der Prozess zur Bewertung des Reifegrads auf der Grundlage der MSLE-Ontologie ist in Abbildung 5 dargestellt.
Abbildung 5: Bewertung des Reifegrads auf Grundlage der MSLE-Ontologie.
M4.1
Erste Testphase semantisch vernetzter Materialdatenportale
Dieser Meilenstein stellt grundlegende Festlegungen, die Architekturdefinition und Toolsetauswahl dar. Die Realisierung von semantisch vernetzten Materialdatenportalen erfolgt größtenteils nach Monat 15.
Es konnte im vierten Quartal 2020 wesentlich an der DCAT Schnittstelle zu NOMAD gearbeitet werden. Die neue NOMAD API muss noch in Details angepasst werden, jedoch kann sie bereits zur Aggregation der DCAT Daten durch eine CKAN Instanz verwendet werden. Im Laufe von 2020 wurde der Architekturplan für AP4 überarbeitet und durch weitere Details ergänzt, Abbildung 6 stellt den aktuellen Stand dar.
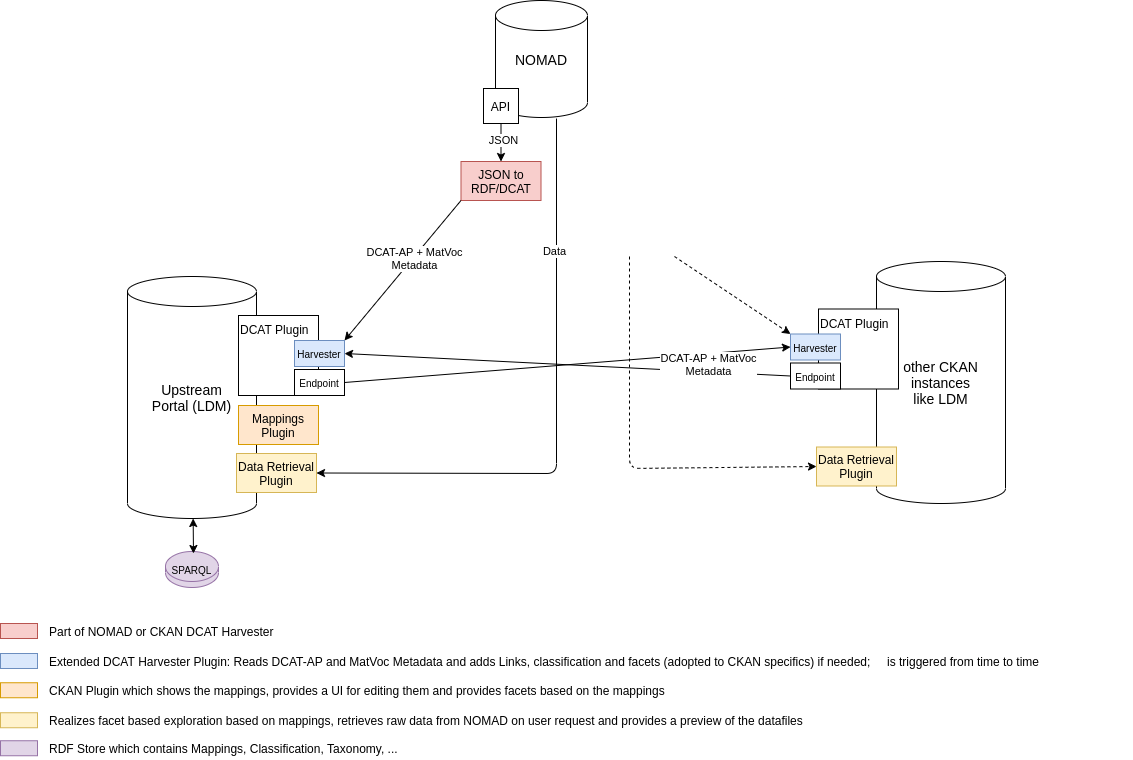
Die Übersicht geht von einer zunächst zentralen Instanz des Leibniz Data Manager aus, welche als Upstream Datenportal für Metadaten aus den Datenrepositories NOMAD und DSMS fungiert. Die Datenrepositories erhalten DCAT Schnittstellen welche von den existierenden CKAN Erweiterungen ckanext-harvest und ckanext-dcat im Zusammenspiel angesprochen werden können und eine add-hoc Synchronisation ermöglichen. Da durch Aktivierung dieser Erweiterungen auch eine DCAT Schnittstelle geöffnet wird, können zukünftig beliebige CKAN Instanzen (In der Abbildung angedeutet) sich beliebig an die Metadatensynchronisation anschließen.
Die Daten aus den Datenrepositories sollen nur bei Nutzeraktionen teilweise abgerufen und gezielt zur Verfügung gestellt werden. Es ist nicht geplant die Daten zu spiegeln oder anderweitig länger zu speichern. Abgerufene Daten sollen für einfache Visualisierungen und Datenverarbeitung zum Einsatz kommen. Dies wird mit dem Data Retrieval Plugin realisiert, welches auch zum Einsatz kommen wird, wenn die Daten mit Mappings zu RDF transformiert werden.
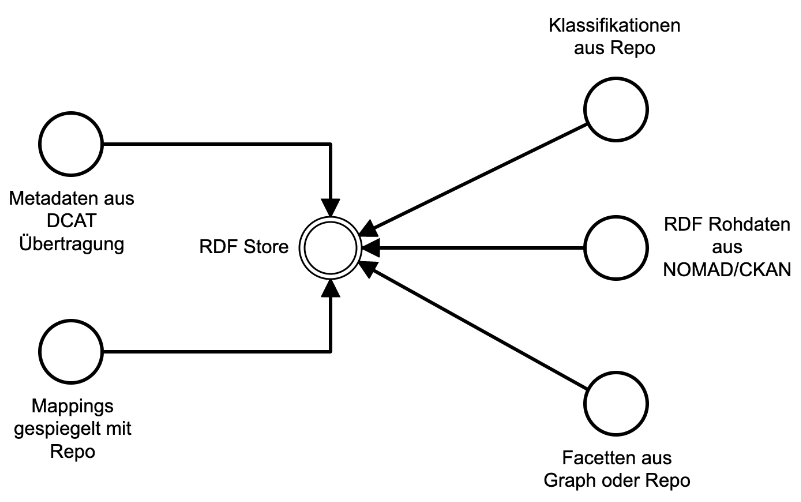
Der LDM ist mit einem SPARQL Endpunkt verbunden in welchem verschiedene Graphen gespeichert werden, siehe untere Abbildung. Außerdem werden in diesem Endpunkt die Metadaten im DCAT Format gespiegelt um diese für SPARQL Anfragen bereitstellen zu können. Daraus ergeben sich weitere Anwendungsmöglichkeiten.
Aus T3.3 und T4.5 wurde abgeleitet, ein Mapping Plugin für CKAN zu erstellen welches die Aufgaben größtenteils umsetzt. Neben Benutzerschnittstellen für die Kuratierung der Mappings, wird es die allgemeine Suche in CKAN mit Informationen über vorhandene Mappings ergänzen. Es werden zusätzlich Services verwendet, die die Daten der Datenrepositories anhand der Mappings in RDF transformieren und den Nutzern zum Abruf bzw. der CKAN Instanz für einfache Visualisierungen bereitstellen.
Der Plan zur semantischen Vernetzung von Materialdatenportalen sieht eine eingeschränkte und fest definierte Synchronisation der Metadaten vor. Die Umsetzung muss durch das InfAI, IWM und FHI erfolgen, da das Arbeitspaket mit anderen verknüpft ist und manche Aufgabenbereiche nicht aufgeteilt werden können.
Nachfolgend werden die Schwächen und Stärken der Architektur bzw. des Gesamtkonzeptes aufgelistet.
Stärken:
- Auf Grund der Verwendung von CKAN und der vorhandenen offiziellen Extensions, ist es ohne Eigenimplementierungen möglich weitere CKAN Instanzen als Upstream Metadatenportal oder Teilnehmer in der Synchronisation anzuschließen.
- Der Datenaustausch ist durch DCAT zukunftsfähig. DCAT ist ein offener und verbreiteter Standard. Da grundlegend nur Metadaten ausgetauscht werden ist die durchschnittliche Datenbandbreite gering und das Austauschformat einheitlich. Neue Datenrepositories müssen nur die DCAT Schnittstelle bereitstellen und Digital Object Identifier unterstützen.
- Das Konzept berücksichtigt die Aufgaben aus allen Arbeitspaketen, sodass ein Arbeitspakete übergreifendes System vorangetrieben wird.
- Das Tooling soll komplett FOSS (free and open-source software) sein und somit für nicht kommerzielle Digitalisierungsprojekte kostenlos nutzbar.
Schwächen:
- Da nur ausgewählte Teile der Daten aus den Repositories in der Upstream Instanz geladen und verarbeitet werden, sind nur einfache Visualisierungen möglich. Geplant ist Visualisierungen an die Datenrepositories auszulagern.
- Zur Realisierung müssen im Projekt die mappings- und retrieval Extensions sowie eigene Webservices umgesetzt werden.
- Anpassungen des Upstream Datenportals für die Verwendung der Klassifikationen, Mappings und Facetten müssen manuell auf zusätzliche Datenportale, die synchronisiert werden sollen, übertragen werden. Geplant ist die Anpassungen als eigene installierbare Extensions bereitzustellen.
- Es findet keine Versionierung der Metadaten statt. Einzig die Ontologie wird mit git versioniert.